Senior / Lead Data Engineer (Python / AWS / Spark)
Share it on:
July 31, 2025
Engineering
Full time
Remote
Senior level
2800 to 6000 USD
$ 2800 to 6000 USD
Amazon Web Services (AWS)
Apache Kafka
Apache Spark
Data Engineering
Python
English advanced
14 talents have already applied, you are still on time!
HE
JV
RG
Share it on:
About the Role
We are looking for a Senior or Lead Data Engineer to be the founding member of our new data team. In this high-impact role, you’ll report directly to the CTO and play a critical part in shaping the future of data at our company. You will work across three distinct product lines to standardize and unify data pipelines, processes, and governance. This is a unique opportunity to build from the ground up and influence data architecture and strategy at a multi-product SaaS company.
Responsibilities
Design, build, and optimize scalable data pipelines using Apache Spark, Kafka, and related tools
Develop and orchestrate data workflows using Apache Airflow
Architect and manage infrastructure in AWS, including services like S3, Kinesis, Lambda, EMR, Glue, and Redshift
Build and support real-time data pipelines and event-driven systems for streaming data ingestion and processing
Establish standardized data ingestion, transformation, and storage processes across multiple product lines
Work closely with product and engineering teams to unify and document data models and schemas
Ensure data quality, lineage, and observability across all pipelines
Lead data governance, compliance, and security practices from day one
Mentor future hires and define engineering standards as the data team grows
Qualifications
5+ years of experience in data engineering, ideally in SaaS or multi-product environments
Expertise in AWS services relevant to data infrastructure (S3, Glue, Redshift, EMR, Lambda, Kinesis, etc.)
Strong proficiency in Python for building pipelines, ETL/ELT jobs, and infrastructure automation
Deep hands-on experience with Apache Spark, Kafka, and the broader Apache ecosystem
Proven success designing and supporting real-time data streams and batch workflows
Solid experience with Airflow or equivalent orchestration tools
Strong understanding of distributed systems, data architecture, and scalable design patterns
Passion for clean, maintainable code and building robust, fault-tolerant systems
Nice to Have
Experience with Delta Lake, Apache Iceberg, or Apache Hudi
Familiarity with containerized workloads (Docker, Kubernetes, ECS/EKS)
Background in building internal data platforms or centralized data lakes
Experience supporting data science and BI/analytics teams
Knowledge of data privacy, compliance, and security practices (e.g., SOC 2, GDPR)
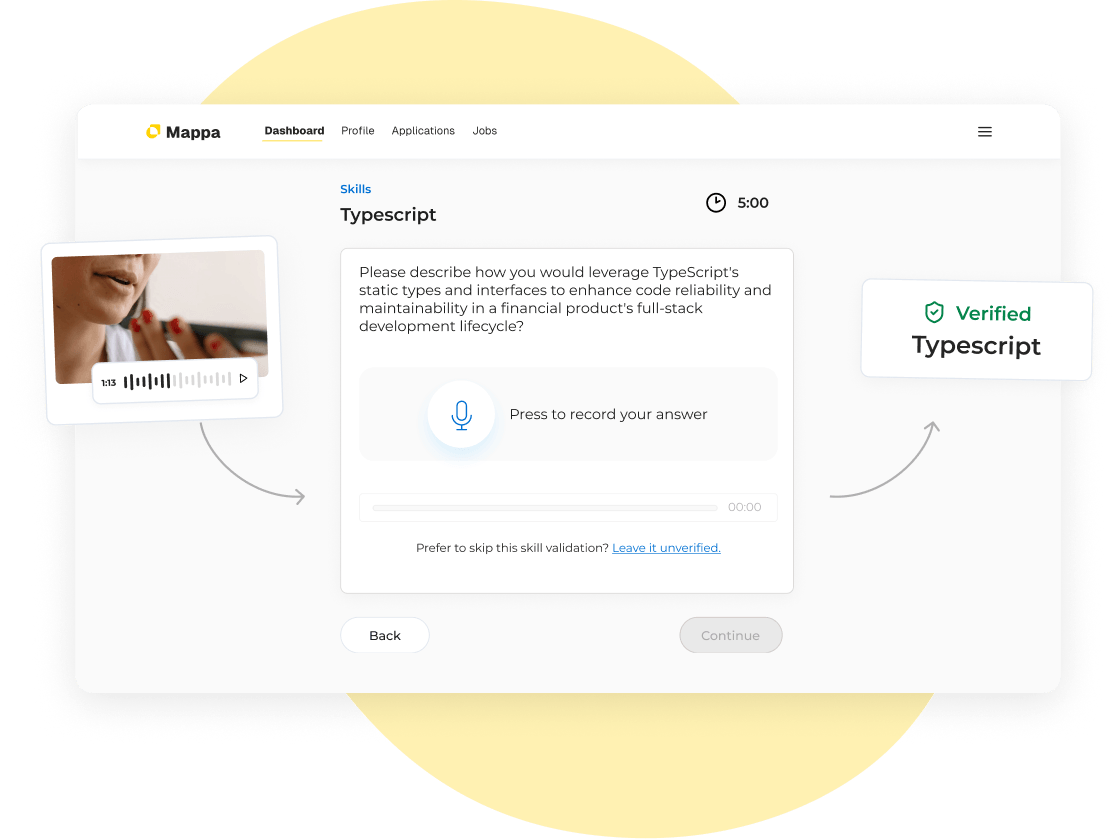
Quickly validate your skills through audio responses while applying—It's just like recording an audio on WhatsApp.
1
Apply for a job
Our AI-powered matching algorithm considers over 100,000 data points to curate a thoroughly vetted shortlist just for you.
2
Get matched
We analyze the nuances of your voice, your career so far, and the quality of your audio responses to mapp your profile and match you with the right company.
2
Get matched
Our AI-powered matching algorithm considers over 100,000 data points to curate a thoroughly vetted shortlist just for you.
3
Meet the company
We’ll highlight all the reasons why the company should hire you, and you will receive an invitation for an interview to showcase those reasons.
3
Meet the company
Our AI-powered matching algorithm considers over 100,000 data points to curate a thoroughly vetted shortlist just for you.
4
Get hired
Mappa will handle everything from contract to payment, allowing you to focus on delivering your best work.
4
Get hired
Our AI-powered matching algorithm considers over 100,000 data points to curate a thoroughly vetted shortlist just for you.